
A little more on Spring tests - our optimizations
Damian Kaczmarczyk,
Mateusz Chrzonstowski
December 11, 2023
In the previous article we covered good practices for writing tests. Here, we focus more on our road toward executing them faster, especially on CI.
Something working for us not necessarily will work for you, but we provide our subjective “effort vs. gain” estimates, so you can quickly see where we got the boost from, check if similar things are slowing your CI down, and consider investing time in them or not.
50 shades of Spring context
One thing emphasized in the previous article was to focus on sharing test annotations. Sometimes, you can still find multiple Spring annotations in your codebase though, and it’s important to understand the consequences of having them.
Each of:
@WebMvcTest@SpringJUnitWebConfig@DataLdapTest@DataMongoTest@SpringJUnitConfig@DataJdbcTest@DataRedisTest
might start reasonably fast as it only loads a subset of Spring context (just required beans for handling HTTP,
just required beans for databases, just listed beans, etc.), but having them all might sum up a lot of time. An
alternative would be to start one, big context with @SpringBootTest and then it’d be started just once, cached, and
reused for all tests.
From a CI perspective, where you run all the tests anyway, it might be a very important decision to make.
Am I truly having a single context?
Even if you have just a single @SpringBootTest annotation in your project, you might still have multiple contexts
starting up. Take a quick look at your logs from tests and count how many times you see a famous Spring logo:
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.7.15)
Each occurrence means a new context is starting up, but to get a full picture, check logs after configuring:
logging.level:
org.springframework.test.context.cache: DEBUG
You should find something like this (normally a one-liner, but split for readability):
Spring test ApplicationContext cache statistics:
[DefaultContextCache@10fc1a22
size = 1,
maxSize = 32,
parentContextCount = 0,
hitCount = 6,
missCount = 1
]
Above we luckily have just a single context (size = 1), but as you can read, there might be up to 32 contexts cached.
It all happens thanks to SpringExtension, but under the hood, it utilizes a static object with a map typed
as Map<MergedContextConfiguration, ApplicationContext>.
How keys are generated for this map? There are multiple ingredients of MergedContextConfiguration, but each time you
add:
@TestPropertySource@DynamicPropertySource@ActiveProfiles@ContextConfiguration@MockBean@SpyBean@Import
somewhere in tests, you basically end up with a new context to start. E.g. @MockBean registers a new thing in Spring,
usually overriding the base one. Each time you have different beans or different properties/profiles resulting in new
beans, you end up with a new context, so it’s not that hard to get more than a single one.
There is also another annotation (which should be probably prohibited) - @DirtiesContext. It basically tells to not
cache the context, so it’s a performance killer. This single annotation was the main source of problems for Philip
Riecks, and he summarized them in his talk How fixing a broken window cut down our build time by
50%.

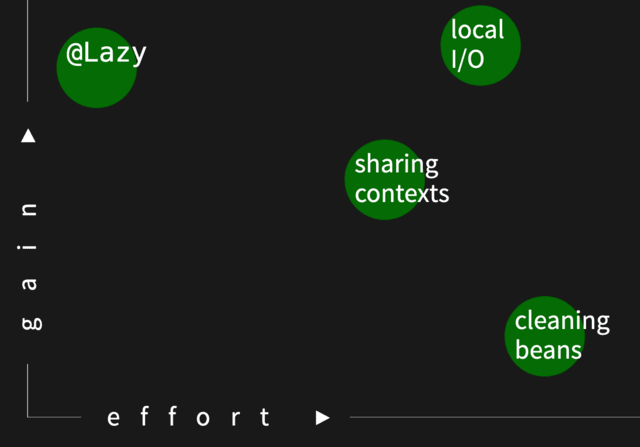
In our subjective “effort vs. gain” scale, we put lowering the number of contexts as a high gain, but with some work to
do. In our case, most contexts were coming from @MockBean and @SpyBean, so we just needed to set up underlying beans
rather than mocking them in individual tests. Luckily, some of them were not even used, so we could just remove them.
Another popular source of contexts in our codebase was various properties, and we did our best to set the majority of
them just in a base class (e.g. WireMock URLs could all coexist as they were for simulating different systems).
Going deeper - lazy initialization
How to further tune our context? Let’s focus on its startup time.
Usually, @Lazy next to the bean injection is used as an ugly workaround for cyclic dependencies (A requires B,
which requires C, which requires A). We don’t encourage using it in the production code, but how about registering
everything in tests in a lazy way?
spring:
main:
lazy-initialization: true
It appeared to be super effective for us. Our codebase is not fully covered with integration tests and even in well-tested systems, you probably don’t need Actuator, some thread pools, and other things that normally start up with Spring.
Also, even when limiting the number of contexts, you might still end up with a few of them, and it might be like the first needs just 60% of beans, while another uses 50% (some of the previous ones plus the remaining 40%), and last uses just 10%, etc. Then, just a required part of beans will fully start everywhere thanks to the above single property.
Last but not least, even if not having any boost at all (as your integration tests cover everything, and you have just a
single context), lazy init can still help, e.g. when developing an isolated feature, for which you constantly run just a
single integration test class (which doesn’t need all the beans). Lazy initialization works then similarly to having
just @SpringJUnitConfig listing just required beans for that test (faster startup time).
However, one thing to remember is that if your code has an actual cyclic dependency, preventing Spring context from starting, your tests won’t discover this. It wasn’t a problem for us though, as we already had a dedicated step in our pipeline for checking if app is able to start with the production configuration.

Worth emphasizing that after using this setup for more than a year we still recommend it. There was just a small number of cases, where we needed to explicitly inject something in tests to load it, and it took us minutes to realize, as we all knew what setup we have. Example for cache metrics we were asserting against:
@Autowired
CacheTest(
@Qualifier(PARTICULAR_CACHE_MANAGER) CacheManager caches,
CacheMetricsRegistrar eagerInitForMetrics) {
assert eagerInitForMetrics != null;
closer.register(() -> caches.getCache(PARTICULAR_CACHE).clear());
}
Removing unnecessary beans
Encouraged by the previous success, we decided to go even further and remove unnecessary beans from the context. The first challenge was to find them, but there is yet another configuration property one can use:
debug: true
It provides CONDITIONS EVALUATION REPORT showing what was picked up, and thanks to which conditions.
Another approach is to use the /actuator/beans endpoint, but you should use it in each integration test context
separately, so it’s not super easy, especially when having multiple apps starting on different random ports and not
being fully sure which started where.

At the end of the first iteration, it appeared we were too eager to start it, and we should rather find more evidence that it might be worth the effort. We introduced some cleanup though, so it ended up being boy scouting, not an optimization.
However, in 2024, we got to know about a pretty new tool, spring-startup-analyzer, and with its help we could clean our context e.g. from HBase as it wasn’t needed in most tests, yet it appeared to take some time to start.
IO dependencies
IO is a common source of problems when it comes to performance. Not only in tests but in our case especially there, as we had some tests calling the dev environment.
We started a parallel effort to move such tests into a separate flow, but also to test, especially our Redis integration, better.
Many folks might now think of Testcontainers, but for Testcontainers you need Docker on developers’ machines and CI agents, and it’s not always possible. In one codebase we decided to go with shared, local, embedded Redis instead and that change alone decreased the execution time of our integration tests on CI from 27 to 16 minutes.
When sharing the same Redis instance, we had to make sure to clean it properly or to use different keys for each test. We went with the latter, as it was similar to how we were using it when calling Redis on the dev environment.
However, in a smaller app, with lower number of contributors, we decided to go with Testcontainers and one of the challenges was to make the local setup smooth for developers. In the end we’ve chosen Rancher Desktop for that.
We also came up with the example repo showing various context (sliced, shared) and Testcontainers (restarting, shared, reused) patterns you might want to check: downloads-service.
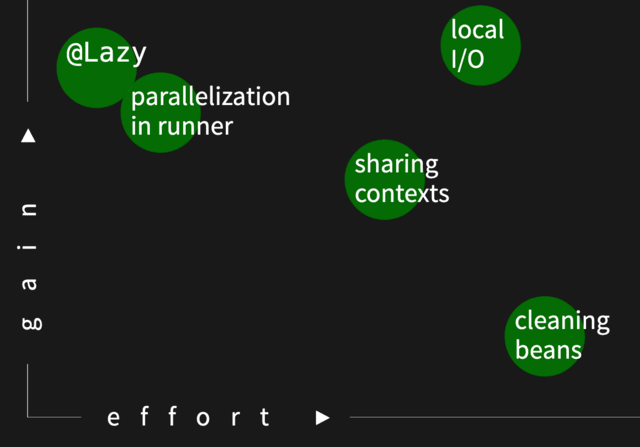
Parallelization
Multi-threading is a common way of speeding things up, but also a risky one. Not only you need to be careful about
“normal” shared resources, but also all the static fields and singletons one put in tests not considering their
parallel execution.
We analyzed 2 options for parallelization:
- With the build tool (Gradle in our case)
- With test framework (JUnit 5)
It quickly appeared first parallelizes with processes (and different JVMs), so context caching described above was not
working as well as it could. Also, Gradle didn’t allow concurrent test method execution, and it appeared to work
best to focus just on a limited number of classes, but with scores of tests (Pareto’s principle in action). And it’s
enough to have @ParameterizedTest to have “scores of tests” in a class.
Not a surprise we added:
junit.jupiter.execution.parallel.enabled=true
and
@Execution(ExecutionMode.CONCURRENT)
class ConcurrentTest extends IntegrationTest {
/* ... */
}
here and there, and enjoyed the boost from parallel test method execution within multiple threads. As mentioned, we focused on limited test classes, especially those testing something with Redis.
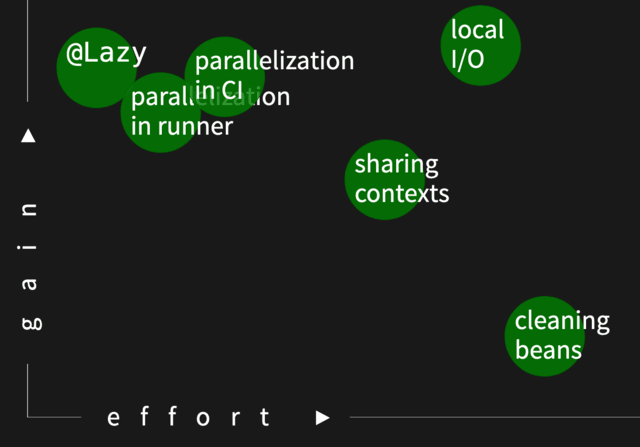
Further parallelization
Enjoying parallelization, we quickly realized our different tags, already grouping tests e.g. from different app “modes”, could just run in parallel on our Jenkins build agents:
stage('Tests') {
parallel { // we added this
stage('Unit tests') {
steps {
sh "./gradlew test"
}
}
stage('Integration tests') {
steps {
sh "./gradlew integrationTest"
}
}
stage('Integration tests intl') {
steps {
sh "./gradlew integrationTestIntl"
}
}
// ...
}
}
The same can be achieved with other CI systems, e.g. by using different jobs in GitHub Actions.
The problematic thing was Gradle locking, but we just needed to ensure compilation of test sources happens before tests, and all the parallel tests run on top of already compiled classes.
Last words
In the end, we went from 32 to 10 minutes for our CI pipeline, and we called it a day. We could probably go even further, but you need to stop somewhere, and we were happy with the result. We also decided to utilize our time for spreading the knowledge and ensuring team members are aware of the changes, and they won’t add more contexts or move away from any other optimizations we introduced.


